Hi All, My name is Aleks. Our company is building an audio assessment platform, AIDI. In this article, I’d like to share my experience with an attempt to reduce OpenAI costs using the LLMLingua framework.
Audio Assessment
Leading Voice-to-Text solutions in combination with the latest LLMs allows us to assess conversations using dynamic business criteria that match the business needs and change as the business grows, which opens up a wide range of possibilities for controlling the call center. This was not possible with old-fashioned statistical analysis, where we could only analyze the emotional aspects of the conversation.
On the top level, it works using the following algorithm:
- Transform the audio to text using voice-to-text model
- Use LLM to assess the conversation text
Check out the open source solution to see how this case works in action.
LLM usage considerations
LLM’s, especially GPT-4, come with a great opportunity to empower the model for different tasks. However, there are several things to consider when we are using them for audio assessment tasks.
Prompt length limits
Audio conversations, especially meeting recordings, might be too long. Each model has context-window limitations, such as hard limits, as well as the model’s ability to forget some facts when the context window is fully utilized.

GPT-4 Turbo attempts to fight this limitation with a 128k window; however, it works best when the context window is less than 8k tokens.
We could avoid this data loss by using the map-reduce algorithm for the long conversation assessment or by compressing the prompt.
Cost
GPT-4 models cost a lot, and the final bill after analyzing 10,000 conversations can be painful.

We can consider using GPT-3.5 for such tasks, but it leads to precision loss due to the bad reasoning of the GPT-3.5 model.
The good idea would be to reduce the number of tokens used for the analysis of each conversation. This will help us get the best results out of the model by using only the first 8k tokens and reducing the bill.
This is why a research paper from Microsoft LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models caught our attention. The researchers were able to reduce the number of tokens by 20x with minimal data loss. It sounds ambitious and promising.
LLM Lingua
LLMLingua utilizes a compact, well-trained language model (e.g., GPT2-small, LLaMA-7B) to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models (LLMs), achieving up to 20x compression with minimal performance loss.
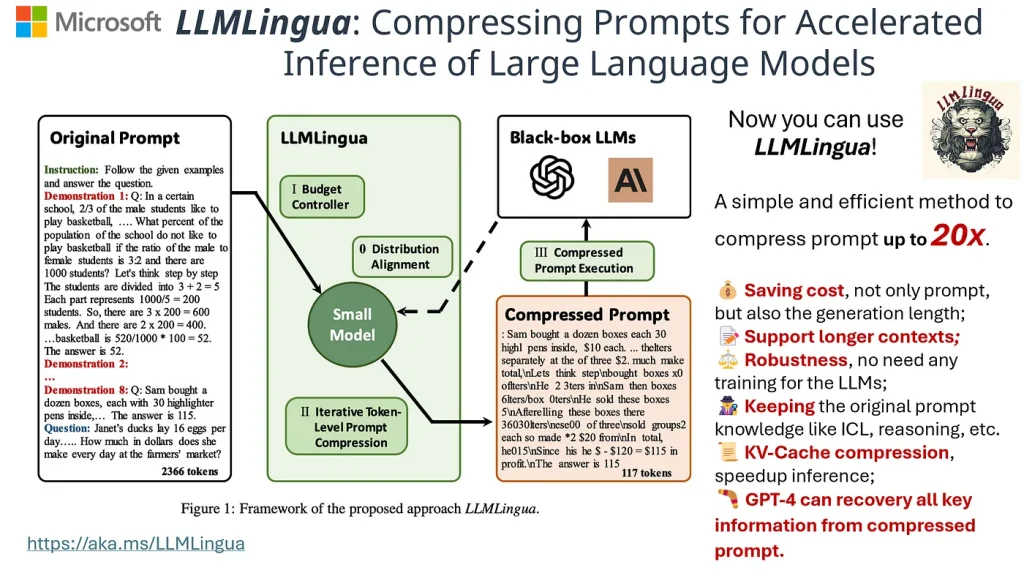
Repo https://github.com/microsoft/LLMLingua
Experiment
For experiments, I’ll use the benchmark created for the AIDI product. It helps us run experiments with different prompts, algorithms, and LLM models.
It has 12 dialogues under the hood and assesses each dialogues with six questions, which should be answered yes or no. We split dialogs into two categories:
- All questions for first six dialogues should be answered as yes
- All questions for the rest of the dialogues should be answered as no.
Finally, we calculate the total LLM score.
LLM Model used — GPT 4 Turbo.
Compression code
I’ll be running the compression model on the CPU, so here is the instruction on how to do that.
First, we have to install two dependencies:
Then compress the prompt using the following code. This code will provide the default 2x compression.
llm_lingua = PromptCompressor(
model_name="NousResearch/Llama-2-7b-hf",
device_map="cpu" # Device environment (e.g., 'cuda', 'cpu', 'mps')
)
compressed = llm_lingua.compress_prompt(prompt)
compressed_prompt = compressed["compressed_prompt"]ConclusionOn the first start, the library downloads the required models. It took about an hour.
Compressing entire prompt
In the first experiment, I tried to compress a prompt as well as a conversation. It took 15 minutes to compress 2,000 tokens using an i5–12400F CPU.
After compression, LLM answered that it couldn’t understand the instruction and asked to provide clear instructions.
So, the compression broke the instruction entirely.
Compressing conversation
In the second experiment, I tried to compress only a conversation.
The instruction worked now, but the precision of the assessment was only 30%, compared to 93% without compression. This means we lost a lot of context during compression.
Conclusion
The idea behind LLM Lingua is natural and ambitious. Unfortunately, currently we can’t utilize the framework for audio assessment because it leads to critical data loss for our scenarios.
Also, it requires powerful resources to run the library. We can’t go to production with the CPU and need to run the model on something powerful like an NVidia A100 CPU, which will lead to a bill increase if you don’t have your own infrastructure.


