Since the writing of my last article, not much time has passed, but progress doesn’t stand still, and several important changes have occurred. Here, I won’t cover the basics — read the original article for that.
Context
The first significant change is the substantial increase in the context window size and the decrease in token costs. For example, the context window size of the largest model Claude from Anthropic is over 200,000 tokens, and according to the latest news, Gemini’s context window can reach up to 10 million tokens. Under these conditions, RAG (Retrieval-Augmented Generation) may not be required for many tasks (or at least not all of its components) since all the data can fit into the context window. We’ve already encountered several financial and analytical projects where the task was completely solved without using a vector database as an intermediate storage. The trend of token cost reduction and context window size increase is likely to continue, reducing the relevance of using external mechanisms for LLMs. However, they are still required for now.
If, however, the context size is still insufficient, different methods of summarization and context compression have been devised. LangChain has introduced a class aimed at this: ConversationSummaryMemory.
llm = OpenAI(temperature=0)
conversation_with_summary = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=OpenAI()),
verbose=True
)
conversation_with_summary.predict(input="Hi, what's up?")
Knowledge Graphs
As the amount of data LLMs have to navigate grows, the ability to navigate this data becomes increasingly important. Sometimes, without being able to analyze the data structure and other attributes, it’s impossible to use them effectively. For example, suppose the data source is a company’s wiki. The wiki has a page with the company’s phone number, but this isn’t explicitly indicated anywhere. So, how does the LLM understand that this is the company’s phone number? It doesn’t, which is why standard RAG won’t provide any information about the company’s phone number (as it sees no connection). How does a person understand that this is the company’s phone number in this case? It’s simple — the page is stored in a subdirectory called “Company Information.” So, a person can understand what the data means from the convention of how the data is stored (i.e., from the structure or metadata) and use it effectively. For LLMs, this problem is solved with Knowledge Graphs with metadata (also known as Knowledge Maps), which means the LLM has not only the raw data but also information about the storage structure and the connections between different data entities. This approach is also known as Graph Retrieval-Augmented Generation (GraphRAG).
Graphs are excellent for representing and storing heterogeneous and interconnected information in a structured form, easily capturing complex relationships and attributes among different types of data, which vector databases struggle with.
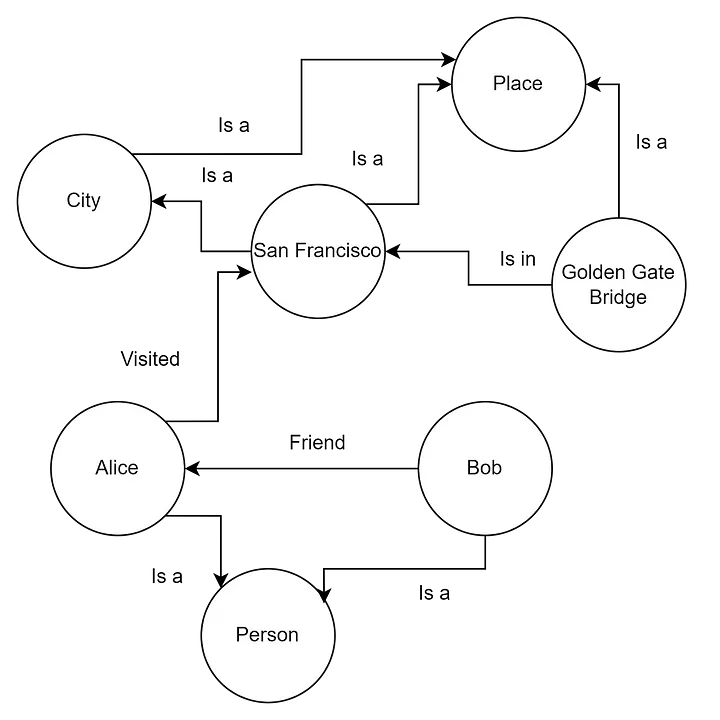
Example of a Knowledge Graph
How to create a Knowledge Graph? This is an interesting question. Usually, this process involves collecting and structuring data, requiring a deep understanding of both the subject area and graph modeling. This process can largely be automated with LLMs (surprise 🙂). Thanks to their understanding of language and context, LLMs can automate significant parts of the Knowledge Graph creation process. By analyzing textual data, these models can identify entities, understand their relationships, and suggest how best to represent them in a graph structure.
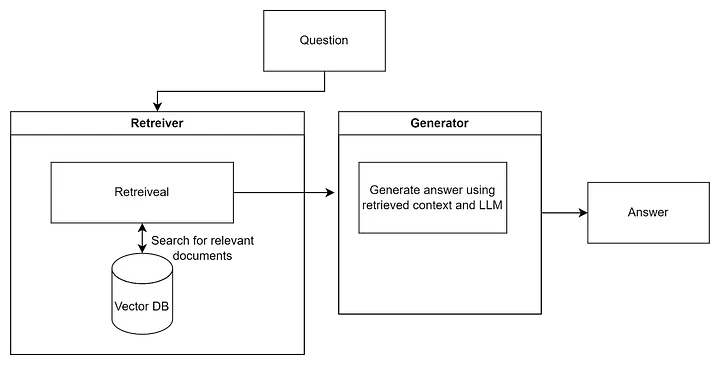
A vanilla RAG looks something like this:
The modified process will look like this:
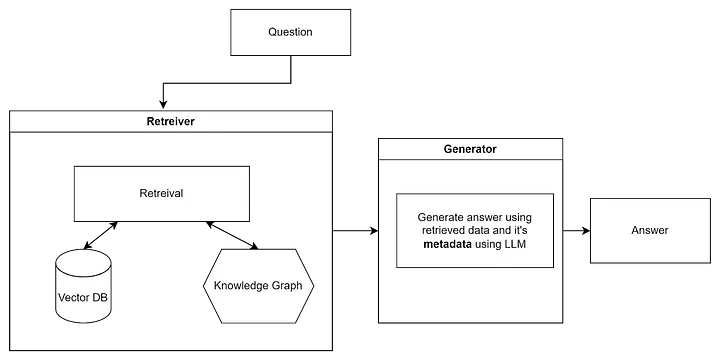
So, in fact, this is an ensemble of a vector database and a knowledge graph. As I mentioned in the section on ensembles in the previous article, they generally improve accuracy and often include a search through a regular database or by keywords (e.g., Elasticsearch).
I won’t describe the vector retriever as it is covered in the first article. But let’s look at the Knowledge Graph Retriever. As mentioned above, the most obvious way is to ask the LLM. For example, a user asks a question about the company’s phone number:
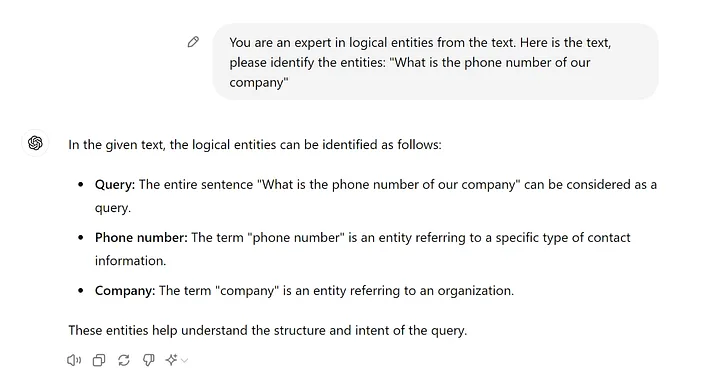
If you do this in code, you can ask to format the found entities in JSON format or use with_structured_output from LangChain. So, the entities from the question are extracted — what next? Next, we’ll look at 100500 use cases from our company on how we applied this 😂. Just kidding. Next, we need to search for these entities in the Knowledge Graph. How this is done depends on where the graph is stored.
There are already many graph storage solutions (though companies often make their own versions), so let’s take Nebula as an example.
documents = parse_and_load_data_from_wiki_including_metadata()
graph_store = NebulaGraphStore(
space_name="Company Wiki",
tags=["entity"]
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
index = KnowledgeGraphIndex.from_documents(
documents,
max_triplets_per_chunk=2,
space_name=space_name,
tags=tags=["entity"]
)
query_engine = index.as_query_engine()
response = query_engine.query("Tell me more about our Company")
As you can see, the search is not much different from searching in a vector database, except that we search for attributes and related entities, not similar vectors. Returning to the first question, since the wiki structure was transferred to the graph, if everything worked correctly, the company’s phone number would be added as a related entity in the graph.
Then, we pass these data and the data from the vector database search to the LLM to generate a complete answer.
It looks simple, but there are a few problems.
Access Control
The first problem is that access to data may not be uniform. In the same wiki, there may be roles and permissions, and not every user can potentially see all the information. This problem also exists for search in the vector database. So, the issue of access management arises. This problem is further complicated by the fact that there are many different approaches and their hybrids, and for example, anyone who has worked with SharePoint knows that those who have will not laugh at the circus.
There is at least Role-Based Access Control (RBAC), Attribute-Based Access Control (ABAC), and Relationship-Based Access Control (ReBAC) and their combinations. Generally speaking, User Directories (like Active Directory), for example, also represent a graph where the access question is approximately “Is there a path from node user U to node resource R.” If such a path exists, access is granted.
Permissions and categories are also a form of metadata, and for this whole system to work, these metadata must be preserved at the Data Ingestion stage in the knowledge graph and vector database. Correspondingly, when searching in the vector database, it is necessary to check on the found documents whether the role or other access attributes correspond to what is available to the user. Some (especially commercial corporate vector) databases already have this functionality as standard. This will not work if the data was embedded in the LLM during training 🙂. Here, one has to rely on the LLM’s reasonableness, and I would not do that for now.
Additionally, it is possible to put a censor (guard) on top, filtering the model’s output if something slips through. Everyone knows Lakera; our company also developed a similar product.
Ingestion and Parsing
Data needs to be somehow inserted into the graph, as well as into the vector database. However, for the graph, the format is critical, as it reflects the data structure and serves as metadata. Here begins the nightmare of all data scientists, also known as PDF format. You can put everything in a PDF: tables, images, text, graphics. But getting it all back out is sometimes impossible (especially nested tables).
There are different frameworks and libraries that do this with varying degrees of success, LLama Parse being the most notable one.
Unfortunately, there is no good solution for this yet, and sometimes it is easier to use OCR or recognize a document image instead of parsing. Maybe someone will create a separate model focused only on parsing PDFs into something more acceptable, but dreaming doesn’t hurt.
In general, the current focus is on improving the quality of answers. Besides using knowledge graphs, there are several approaches:
CRAG (Corrective Retrieval Augmented Generation)
We’ve seen that RAG sometimes gives incorrect results, and different methods can be used to evaluate them, for example, the LLM itself (or some lighter version). If the results are not relevant, prompt correction, graph search, or even Google search can occur. CRAG goes a bit further, offering a framework that automates this process. Essentially, this is another graph, implementing a state machine (surprise 🙂), which looks something like this:
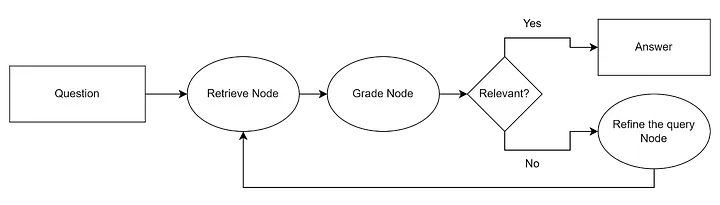
To implement it, it’s easiest to use LangGraph, which will be discussed further.
Self-RAG
Self-reflective RAG is based on research claiming that this approach provides better results than regular RAG. Overall, the idea is very similar to the previous one (CRAG) but goes further. The idea is to fine-tune the LLM to generate self-reflection tokens in addition to the regular ones. This is very convenient, as there is no need to guess how confident the LLM is and what to do with it. The following tokens are generated:
- Retrieve token determines whether D chunks need to be retrieved for a given prompt x. Options: Yes, No, Continue
- ISREL token determines whether chunk d from D is relevant to the given prompt x. Options: relevant and irrelevant
- ISSUP token determines whether the LLM’s response y to chunk d is supported by chunk d. Options: fully supported, partially supported, no support
- ISUSE token determines whether the LLM’s response to each chunk d is a useful answer to the query x. Options represent a usefulness scale from 5 to 1.
Using these tokens, a state machine can be built, using the aforementioned LangGraph, which looks something like this:
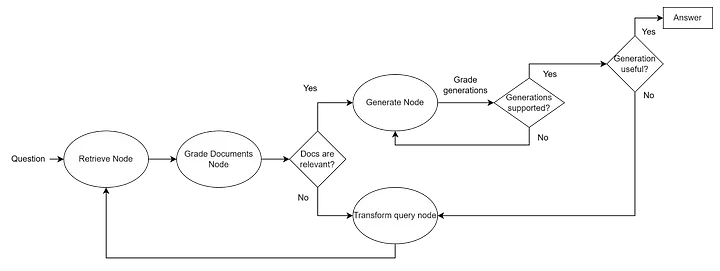
For more details, see here.
HyDe
Another method, similar to RAG Fusion, is that it modifies the usual RAG retrieval process. HyDe stands for Hypothetical Document Embeddings and is based on the study “Precise Zero-Shot Dense Retrieval without Relevance Labels.” The idea is very simple — instead of using the user’s question for searching in the vector database, we use the LLM to generate a response (a virtual hypothetical document) and then use the response for searching in the vector database (to find similar answers).
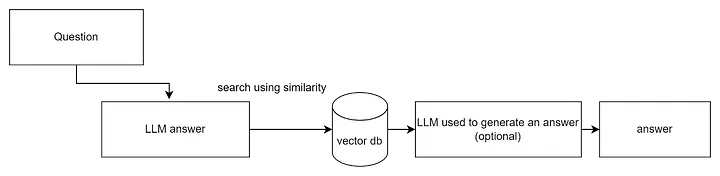
Why all this? Sometimes users’ questions are too abstract and require more context, which the LLM can provide, and without which the search in the database makes no sense.
I think this is not an exhaustive review of the new changes; if I forgot something — write in the comments.


